Say you’ve got some points in a plane, and you’re fixin’ to triangulate them. Specifically, you’re going to generate the Delaunay triangulation with an incremental algorithm, and then of course you’re going to want the triangles and/or segments.

Now say you’re doing this in Java, and you’re doing it many times over, and you’re doing it on battery power, so you have to do it efficiently.
 Now say you’ve implemented the randomized incremental algorithm described in this book. (Good book, by the way.) In short, you begin with one large triangle (large enough to contain all the points you’re going to use), then add points one at a time. Adding a point (pr) involves finding the triangle that contains it (Δ1) and splitting that triangle into three.
Now say you’ve implemented the randomized incremental algorithm described in this book. (Good book, by the way.) In short, you begin with one large triangle (large enough to contain all the points you’re going to use), then add points one at a time. Adding a point (pr) involves finding the triangle that contains it (Δ1) and splitting that triangle into three.
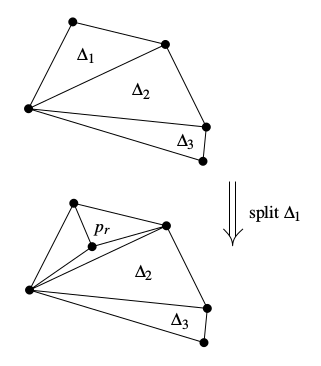
To get this done you could just keep a list of all your triangles and then, for each point inserted, search the list for the triangle that’ll be split, remove it, and add the three split triangles. Technically such a list would qualify as a point location structure, but it’s a costly brute force search. A tree would be a better structure.
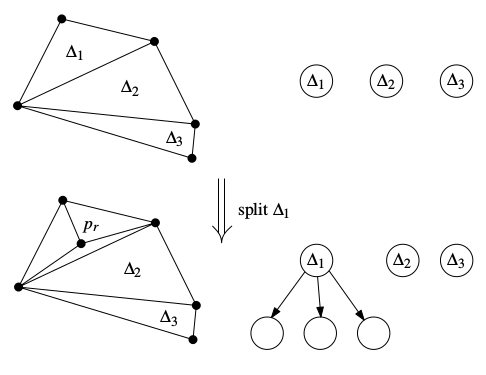
The leaf nodes of this tree correspond to the triangles in the triangulation so far. The node for Δ1 now has three children and is no longer a leaf, but it keeps a record of its original triangle so this structure can be searched. To insert a point: start at the root, determine which child node has a triangle that contains the point, then check that node’s children in turn, and eventually you’ll end up on a leaf node, split its triangle in three, and attach the three new leaves to the old leaf.
Enumerating the triangles after all points have been inserted would be a simple traversal; just ask the root node for all of its leaves, have it ask each of its children, and have them ask their children, and so on. Order is irrelevant, so traverse any way you please.
Enumerating the triangles after all points have been inserted would be a simple traversal if all you ever did was split triangles, but generating the Delaunay triangulation involves another operation: edge flips.
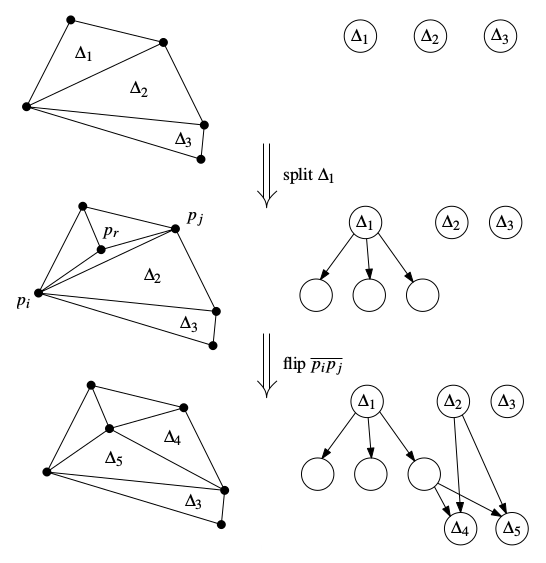
As opposed to splitting, where you get three new triangles from one triangle, edge flipping gives two new triangles to replace two old triangles. Both new triangles overlap both old triangles, so the point location search will only work correctly if both old nodes have both new nodes as children. That means the new nodes Δ4 and Δ5 have more than one parent. That means this structure isn’t a tree any more. It is still a directed acyclic graph, but a simple tree traversal will encounter each of the new nodes twice, once from each parent. That redundancy compounds, and you’ll get many duplicate triangles in your enumeration. Many. I made this mistake, and I got something like 7,000 triangles where I expected 30.
One way to get only distinct triangles would be to go ahead with tree-like traversal and add each triangle to a Set to eliminate/ignore the duplicates. It’s not a good way, but it would be correct. There’s a simple solution to this problem: add a flag to the nodes which, if set, causes them to abort any traversal and return nothing. Whenever two old triangles are replaced by two new triangles, set this flag on one of the old nodes, so for enumeration the two new nodes are only visited once via the other old node. The flag is ignored for point location searching.
So you’ve got your distinct triangles, but what if you need less information than that? What if you just want to know which pairs of points are connected by an edge? You could take the distinct triangles and add each of their three edges to one big set. This isn’t as bad as using a set to eliminate duplicate triangles because the duplication here is strictly limited; each edge occurs in at most two triangles.
I got satisfactory performance with the edge set approach, but it did have a pretty awful “churn” problem. Every edge is represented by a pair of values, one value for each vertex, and trying to insert an edge into the set necessitates creating a pair object. That adds up to a lot of allocating and deallocating every time you generate a triangulation, and that keeps the garbage collector very very busy. You could pool pairs, you could re-use whatever collection object you use to return the distinct edges, but there’s a better way.
Getting the distinct edges from the triangulation’s point location structure can be done without pair objects or sets or lists or any other additional structure.
If you construct your point location structure such that all triangles have the same winding, you can identify and ignore redundant edges immediately, during the traversal itself.
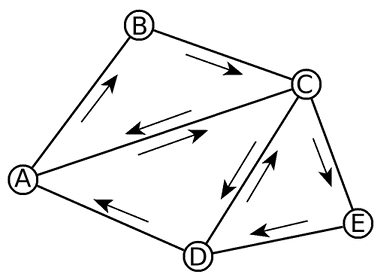
In this diagram there are three triangles which are all wound clockwise e.g. ABC is one of the triangles, but BAC, the reverse, is not. Look what happens at the shared edges. Triangle ABC and triangle CDA share an edge that connects A and C, but they’re oriented differently, like two separate half-edges. ABC has an edge C-A, but CDA has an edge A-C. CDA has an edge C-D, but CED has an edge D-C. All you need to do is distinguish the two different orderings and ignore one.
I’m using primitive integers to identify vertices, so distinguishing the two orders is simple, it just takes a less-than comparison. The equivalent in the diagram above would be alphabetical order. ABC does not contribute edge C-A, CDA does contribute edge A-C. CDA also contributes edge C-D, while CED does not contribute D-C.
This leaves one last place to trim the fat: the structure’s returned list of distinct edges. For my purposes I only need to iterate over the edges once, so instead of returning a list from the structure I supply the structure with an object that accepts edges one at a time. The structure has a method like:
void putEdges(GraphEdgeConsumer consumer)
and GraphEdgeConsumer is an interface specifying a method like:
void putGraphEdge(int a, int b)
I don’t think it’s going to get any better than the point location structure itself directly calling a method and passing two primitives.









